I’ve been lucky enough to have some spare time to look at projects of my own this year, so I researched and implemented a number of trading algorithms on various crypto currency exchanges.
Investing vs trading:
Before we start, though, a quick disclaimer: I’m undecided on the merits of crypto currency as an asset class. My intention here was to implement one or more algorithms to hunt arbitrage opportunities and, upon finding them, make the trades that would implement them. Where I have taken exposure to crypto currencies, I have both won and lost. Consequently, I don’t consider myself to be invested in crypto currencies, as I can’t foretell the future of the asset class with sufficient certainty for my somewhat risk-averse predilections. I’m happy to trade it, though – particularly if I can do so in a manner which minimises my exposure.
Why crypto currencies, not traditional exchanges:
For me there are three reasons which made crypto currencies a good learning ground for this sort of exercise:
- It’s generally accepted that the crypto currency markets are fairly inefficient, meaning that arbitrage opportunities abound. This may be because the asset class (without discussing the merits of such a label) is in its relative infancy, and it may also be because there are a large number of new, as-yet relatively unexplored exchanges.
- Crypto currencies are extremely volatile, which means they’re likely to move faster and further than traditional asset classes. Arbitrage is based on the differentials between prices or returns on (typically correlated) assets. More movement means a greater frequency of those differentials occurring.
- Crypto currency exchanges are created by IT people, and their APIs (Application Programming Interfaces) are fairly unrestricted. I’m not sure about all traditional exchanges, but as an example, the JSE does a full code review of any code which hooks into their exchange. The wild-west of crypto exchanges don’t. It’s also pretty cheap to register and start trading – no monthly stock broker’s fees, etc.
Where to start:
There are two possible places I can see to start with creating a trading algorithm (or algo). These are:
- The theoretical framework for the trade; and
- Collating the data.
Theoretical framework:
I did a lot of reading about different types of arbitrages to determine what might be suitable. In reality, I suspect that just about any trade which exists in a given traditional market could be implemented in a different market (whether traditional or not).
The more complex the theoretical framework for the trade you want to look at, the greater the difficulty in implementing it, and the possibility that it could go wrong. On the other hand, complex trades are likely to be less prolific than trades which are simpler or more vanilla.
The sort of behaviour we’re looking for is [statistical] predictability. This could be in the form of correlation of leading and lagging indicators, it could be a stationary process, it could be misaligned prices, mean reversion, momentum, or, for that matter, anything else which you hypothesize may give you an edge.
The common element in all of the above is that we want to have a better than 50:50 chance of predicting the next move in the price of whatever it is that we’re trading. Sometimes that behaviour is statistical in nature, such as stationary processes (used in pairs trading, for example) and sometimes it’s more simply a function of efficiency in markets, such as misaligned prices.
Collecting data:
You can almost always find relatively clean data to purchase, if you wish to go that route. It has many advantages: It’s easier, possibly cleaner and almost certainly has a better (longer) history than you could get yourself. On the downside, you’re spending your seed capital which you could have used for trading instead! Also, you don’t necessarily have oversight on how the provider has cleaned the data, and the granularity may be incorrect for your purposes.
If you choose instead to collect your own data, bear in mind that historical data may not be easily available, or available at all. This means you might want to start collecting as early on in the process as possible, so that you have something against which to test your trading hypotheses.
I chose to collect my own data. If you’re looking for historical data for traditional markets, you can download dumps from various sources, such as google finance (stocks, currencies), xe.com (currencies), various reserve banks, etc… For traditional markets, I found that this was helpful in trying to understand the data better, but not particularly helpful in testing trading hypotheses. This was almost all down to the lack of granularity of data available for free. However, I understand that traditional market data is available at fine granularity through the likes of Reuters, Bloomberg and other such providers – but read up on how they collect and clean it!
On the crypto currency exchanges, I hooked into multiple exchanges using their APIs and downloaded order book information for relevant instruments (currency pairs, underlying vs future vs option) at a granularity of around a minute, typically. My little downloading app runs on my pc pretty much 24-7, pulling data from a dozen exchanges each minute. I also collect fx data by screen scraping, although I have run into occasional rate limit issues, which seems fair enough to me, albeit it’s frustrating when it happens.
When I first started looking at crypto currencies I found an excellent project on github called ccxt, which is an open source integration into, at time of writing, 115 different crypto exchanges. This allowed me to do a very quick and dirty download of tick data to try and find correlations and misalignment between different exchanges, instruments etc. I used python (anaconda / Jupyter notebooks) for this exercise and stored my data in a Microsoft SQL Server database. (Both of these are free downloads, although there are some limitations on free SQL Server.)
What data to fetch:
If you haven’t decided exactly trade you’re going to implement, and therefore don’t have sight of your specific data requirements, I recommend fetching per-minute tick data from an assortment of exchanges which may be relevant to you (because you think they’re safe, the instruments being traded are of interest, the geographies work and the volume and liquidity on the exchange is sufficient for your purposes, for example). Collect data for instruments which are of interest – rather too much than too little, since you can always delete it, but can’t go back and collect it again. Initially I started collecting the market ticker information, but I abandoned that fairly soon in favour of only order book data – or at least the top several levels. I currently fetch ten order book levels, although that may be overkill, since I’ve yet to actually use anything other than the top level of the book. As mentioned above, I also collect the fiat fx rate for each order book fetch which has a fiat side (eg USD-BTC) back to a common currency. As I’m based in South Africa, that was ZAR, but you should use whatever works for you, obviously. Given that you’ll be making dozen’s of order book fetches every minute, I recommend storing the fiat fx rate locally periodically and referencing that (or pay for a service provider that doesn’t mind you hammering their server).
You’ll probably also want to fetch any underlying for any derivative instruments you’re collating information on – such as the index for a futures contract.
Finally, I recommend multi-threading your data collection. Although it’s more complex than a single-threaded application, this allows the time differential between data fetches on different exchanges to be smaller. By way of example, a single-threaded application might fetch data at 10:00:00 on exchange A, 10:00:05 on exchange B…. 10:00:30 on exchange Z. If you want to identify price misalignment between exchange A and Z, you will not know what portion of any misalignment you identify results from differences between the exchanges, and what results from change in the underlying price between 10:00:00 and 10:00:30.
Admittedly, you could be a bit obsessive about this. Spurious Accuracy and all of that…
Hypothesis testing:
We now have a gross hypothesis, and the data to test it. So how do we go about doing so?
In the simplest form, we need to simulate the trade we wish to do. However, a trade will be dependent upon some detailed assumptions and decisions (i.e. parameters). We should therefore find and test these parameters. This is something of an iterative process.
Parameterisation:
Firstly, what sort of parameters are we envisaging here? Examples that come to mind include:
- The period of the data we’re looking at to determine the behaviour of the next tick (Last month’s worth? Last hour’s?)
- The granularity of the data (minute, hour, day, second, microsecond)?
- The underlying instruments we’ll be trading (base token (which currency pair?), future (which strike date?), option (put, call?))
- The exchanges we’ll be looking at
- The measures we’ll be using (standard deviation, correlation coefficients, mean return, direction, SMA, EWMA… many many to chose from)
There will be a number of different ways to determine and optimise the parameters for our trade. Remember that we’re looking for predictive relationships, which implies that correlation (or covariance) is a great place to start. If that’s a starting point you’d like to try, then you want to sort your data into leading indicators (input data) and lagging variables (the subject of your investigation). I found Anaconda python, numpy and SciKit Learn to be fantastic tools for this (A quick aside: I am constantly amazed and gratified by the number of super-clever people out there who create these tools and then make them available to everyone for no cost!). I found that identifying the covariance between leading and lagging indicators was a good starting point and then testing whether than might translate into a trade using simple regression worked pretty well for me.
A few points about this stage of the process: I found several warning references in literature regarding overfitting. I did try out various machine learning frameworks (Keras and Tensorflow’s neural networks and recurrent neural networks, for example.) However, I eventually abandoned them in favour of simpler methods. I’m not saying that I won’t go back to them, but it felt a bit like smashing a nut with a sledge hammer – the tools may have been a bit overpowered for what I wanted to do, and I was not able to predict the problems that might arise – which clearly you want to avoid if there’s real money on the line.
Simulating the trade (or “backtesting”):
Having identified a starting set of parameters, the next stage is to simulate the trade. You can do this with various levels of cleanliness, and it’s good practice to start dirty and then clean up if the trade looks like it might work.
Given we’re trying to implement an algo, your simulation should look something like this:
Start loop through time (t):
—If some condition exists:
——Execute trade 1
—If another condition exists:
——Execute trade 2
…etc…
Move to next time step
Initially, I recommend that you don’t bother with fees, volumes, lag times for hitting the exchange, etc – just see if the decisions that you make to trade result in a profit or loss, and what the variability of that profit or loss is. If you make a profit, but first lost more than your capital, then the trade may be too risky to implement. You can also use risk-adjusted return measures, such as a Sharpe Ratio, to measure the success of your trade. Ideally you want a profit curve that slopes consistently upwards, with any downward swings being limited in size (obvious, I know!) My point is that certain trades may be very profitable, but just too risky – I abandoned a number of trades which are more profitable than the ones I landed up implementing because of this.
You also want to watch out for spurious profits – eg, if my algo was simply a decision to buy BTC under any circumstances, and I backtested my decision to buy BTC over 2017, my algo would have looked immensely successful. If I had then implemented it in live in 2018, I would have been crushed.
Once you have done your simple back test, and if the results are encouraging, you should increase the detail of the back test. In particular, you should implement the fees. Other things to look at include:
- The amount of collateral or margin you’re using relative to your available limits – you should limit your maximum position such that the probability that your margin requirement increases above your available margin is below an acceptable probability;
- The volume available at the prices that trigger your decisions to trade – if there’s almost no volume available at those prices, then no matter how high the return of your trade, the trade won’t be able to execute sufficiently to justify the time spent in coding it;
- Lag times for hitting the exchange – if you are not going to be able to hit the exchange with zero lag upon the conditions for trading becoming true, what is the impact of the delay?
Tools for backtesting:
I like two (or maybe three) different tools for backtesting.
- I mentioned above that I use SQL Server to store my data. I also use it to create the data dump which I will simulate my trade on. SQL allows me to slice, dice and order the data, build simple comparisons or functions on the data, and to exclude anomalous data. It’s not ideal for detailed loops, though…
- Python: Python has lots of libraries which assist in financial data analysis (like Numpy). If you’re not au fait with any particular tool, and are going to have to learn one to get started, you could do a whole lot worse than Python for this. Python also allows you to save your data in pickles, so you don’t need a database at all, if that’s what works for you.
- Excel and VBA: I discussed using Excel and VBA for my backtesting with a family member who is an algorythmic trading programmer, and was nearly laughed out of the room. (Thanks Steve!) However, there are a few things which Excel has to recommend for itself. I feel that the familiarity of the environment helps you get started quickly, although you will very likely need VBA, so this may be moot if you’re not familiar with it. Not that you can’t do the same with Python, but I also liked creating functions which put out the result of my simulations, and then calling them from tables which laid out the profit with different combinations of input parameters to create a heat map with conditional formatting (which you can also do in Python, now that I think about it).
Python is much quicker at crunching this sort of data than Excel, for a given quality of code.
Fine tuning parameters:
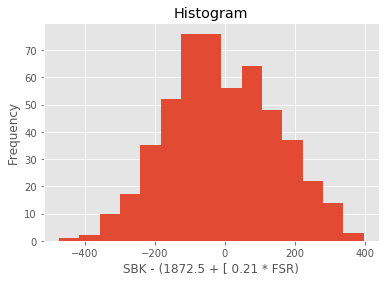
I like to create visual representations of my outputs so I can home in on success and risk easily. Heat maps are good for this.
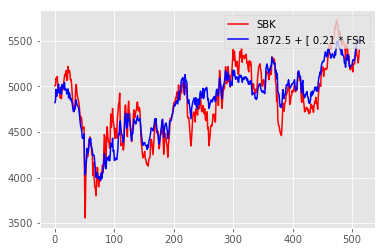
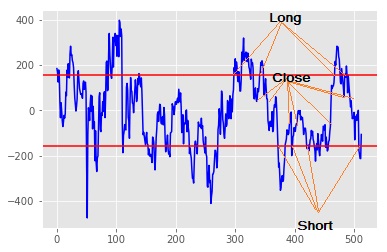
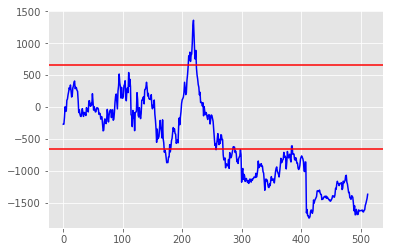
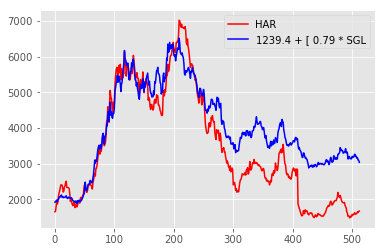
Here’s an example:

The heat map tells us where there are (relatively) successful combinations of input parameters (halfway down on the left) vs unsuccessful (on the right). When choosing parameters based on the heat map, you ideally want to choose a parameter which is not only optimal, but also surrounded by good outcomes. Should the true underlying conditions of the trade change slightly, this should maximise the chances that the outcome will still be relatively optimal. Consequently, in the above map, I would posit that an outcome in the center of the green would be better than a (hypothetical) outcome with an even better profit surrounded by red (i.e. poor) outcomes. The particular algo I was looking at in this example has 6 or so parameters, while clearly you can only (easily) represent two in the heat map. That’s okay – ideally your algo should have local profit maxima with respect to each parameter which are relatively independent of the other parameters. If not, you run the risk that interactions between your parameters may create risk which you don’t understand and cause your algo to lose money. Test this by creating multiple heat maps for parameters outside of the table and seeing if the profit transitions from one table to another in a relatively smooth fashion.
I touched on the dangers of overfitting above very briefly. I don’t think that optimising parameters constitutes overfitting, if you have already chosen your algorithm. However, remain vigilant, particularly if your algo is complex and requires many parameters. (If it is, go and read up on overfitting!)
A second output of my analysis is always a tick-by-tick graph of the profit, showing when trades occurred, what my open position is (to track margin requirements if I’m looking at derivatives), and my current balance (PnL). I usually only create this for trade/parameter sets which are successful / optimal, since I’m not interested in the others anyway. This allows me to identify the track my algo took to get to the optimal outcome. As I mentioned earlier, if I had to lose $1000 first in order to eventually make $100, then the algo is extremely risky relative to the outcome, and probably not worth implementing.
Implementation:
Right, so we’ve now identified a likely-looking trade and we’re ready to implement it.
I initially tried to write a generic framework which I could parameterise to implement any algo. Although this had some success, I became worried that it added more complexity than it was worth – leading to higher latency and greater possibility of error.
I settled on an intermediate approach. I write relatively generic ‘ExchangeMethods’ which hide the complexity of actual interactions with each exchange, but look similar to the rest of my code. Examples of my exchange methods include:
- Market Order
- Limit Order
- Get top price and volume
- Cancel order
- Get open position from exchange
- Get open orders on exchange
- Get collateral balances on exchange
I then write the algo execution code (this will look similar to our pseudo code above) which:
Fetches the [order] data from the exchange
Checks to see if the conditions for opening or closing a position are now true
If so, implements the trades which will open/close the position
loops back to the top and repeats indefinitely
In theory, if I want to use a different exchange or instrument, I can then simply swap out the parameters for my ExchangeMethods and off we go. This is not quite true in practice, but I have managed to implement similar algos to pre-existing ones on new exchanges in under a day, so there is some merit in the approach.
I chose to use C# for my implementation, as I had some pre-existing familiarity with .Net, if not C# itself. However, I would suggest that Python or Java would have been better, because they seem to be more popular, with the result that more of the example code for connecting to different exchanges exists in those languages than C#. For obvious reasons, this can reduce your time-to-delivery for writing exchange methods. I have, however, found C# to be perfectly adequate. It has plenty of literature available, and does everything I need of it. I also like the slightly more structured environment (SDE).
As with data collection, I recommend multi-threading your exchange methods. This allows multiple trades to be placed in the order book at the same time, which may be important if:
- We are trying to trade only when the conditions which trigger our trade are true – they may have changed if we delay our trades; and
- Perhaps even more importantly, if our trade conditions relate to a (possibly calculated) differential between the prices of two or more different instruments. We wouldn’t want to trade one at the ‘correct’ price, but not the other.
I recommend putting a lot of logging into your code, and particularly into your Exchange Methods. This will help you with debugging, and also with determining why your trade is successful or not. Log each decision you’re about to make, and the outcome. Log (nearly) every interaction you make with the exchange (I maxed out by database size logging 100 price fetches per second – hence the ‘nearly’). Log the conditions that apply when you trade, and log the prices and volumes you think you’re making a trade at (the “trigger price”). Some exchanges allow you to place a user-defined data item into your orders. I recommend filling this with, for example, the trigger price, volume, your open position, your collateral balance and a short but meaningful metric which describes why you’ve made the trade. In due course, you should then be able to download your trades and use the custom data item to show how successful you have been in executing at the conditions you thought prevailed. An obvious example: If your trigger price on a buy market order is 1% higher than the price which you actually bought at, then your execution code is probably too slow.
Is exchange microstructure an issue?
Unequivocally…hell yes.
Different exchanges have different microstructures. These are seldom (never?) documented, let alone well documented. They can wreak havoc upon your best code and intentions. Unfortunately determining what the microstructure is seems to be an almost entirely empirical process. I consequently recommend that you start with only a small balance on any given exchange and trade that for a while. I have been caught out by microstructures, lost money because of them, and abandoned algos that looked promising because of problematic microstructures. They waste time and energy (coding for exceptions / unexpected exchange behaviour is difficult!). If you can, read up as much as you can about an exchange before trading on it. If there are lots of questions from confused algo traders… maybe it’s significant!
Another topic which relates to microstructure (sort of) is latency. It may not be clear where your exchange is hosted. If your algo requires low latency, you may want to do some research on this. Hosting your algo in the cloud in specific geographic locations may be helpful – you can test this empirically. I haven’t yet reached the stage where latency is an issue for me, but there is some literature / discussion online about this sort of issue.
Other things to look into:
Without going into too much detail, I suggest the following things are worth looking out for / understanding more of in the context of your trades:
- Margining calculations – I’ve been caught out by this one
- Balancing of equity (collateral) positions, particularly between different exchanges if you’re implementing a trade across more than one exchange – Caught out by this too
- (Unrestricted) ability to withdraw equity – And this
- So-called “Socialised Losses” and Insurance Funds (but not this…yet)
- Rate limits – I’ve had to create lots of extra code to get around rate limits
- FEES! Actually, big fees are as much of an opportunity as a hindrance, since they almost inevitably result in greater differentials
- Leverage
Some metrics:
Time spent on this project: 5 months, nearly full time
Exchanges integrated into: 5 for trading, ~double for data feeds
Algos that worked on paper (or in Excel!) but not on the exchange: Far too many.
Passing shot: Pavlov’s dog
I set a system chime to sound every time my algo traded, which it duly did. However, I initially used the generic Windows system exclamation sound. Which was fine for a while, until I found myself charging off to have a look at my screen every time my wife made an illegal key entry on her laptop. I recommend using a non-standard chime.
If you have any questions about any of the above, please feel free to contact me – contact details elsewhere on the site.